概述
大数据分析比较耗硬件资源,同时软件资源也比较庞大,本文是小编第一次触及大数据环境,适合初学者学习。
资源规划
| 名称 | IP | 主机名 | 备注 |
| master | 192.168.0.200 | master | 主节点 |
| slave-1 | 192.168.0.201 | slave-1 | 子节点 |
1、物理机服务器
2、CentOS 7
3、Hadoop 2.9.2
4、JDK8或以上
5、关闭防火墙Firewalld
")
1、官网下载:https://hadoop.apache.org/releases.html
2、JDK渠道:https://www.oracle.com/cn/java/technologies/javase/javase-jdk8-downloads.html
1、上传至/opt目录
[root@localhost opt]# rz
总用量 499400
-r--------. 1 root root 366447449 6月 23 10:08 hadoop-2.9.2.tar.gz
-rw-r--r--. 1 root root 144935989 6月 23 10:05 jdk-8u291-linux-x64.tar.gz2、分别解压缩源码至指定路径下
[root@localhost opt]# tar xf jdk-8u291-linux-x64.tar.gz -C /usr/local/
[root@localhost opt]# tar xf hadoop-2.9.2.tar.gz -C /usr/local/big/[root@localhost opt]# vim /etc/profile## shift+G尾部添加如下
export JAVA_HOME=/usr/local/jdk1.8.0_291
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/big/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/sbin/:$HADOOP_HOME/bin/:$HIVE_HOME/bin
export HIVE_HOME=/usr/local/big/apache-hive-2.3.9
export HIVE_CONF_DIR=/usr/local/big/apache-hive-2.3.9/conf[root@localhost opt]# source /etc/profile## master节点操作
[root@localhost opt]# hostnamectl set-hostname master
## slave节点操作
[root@localhost opt]# hostnamectl set-hostname slave-1[root@master opt]# vim /etc/hosts
192.168.0.200 master
192.168.0.201 slave-1
[root@slave-1 opt]# vim /etc/hosts
192.168.0.200 master
192.168.0.201 slave-1[root@master opt]# ssh-keygen -t rsa
[root@slave-1 opt]# ssh-keygen -t rsa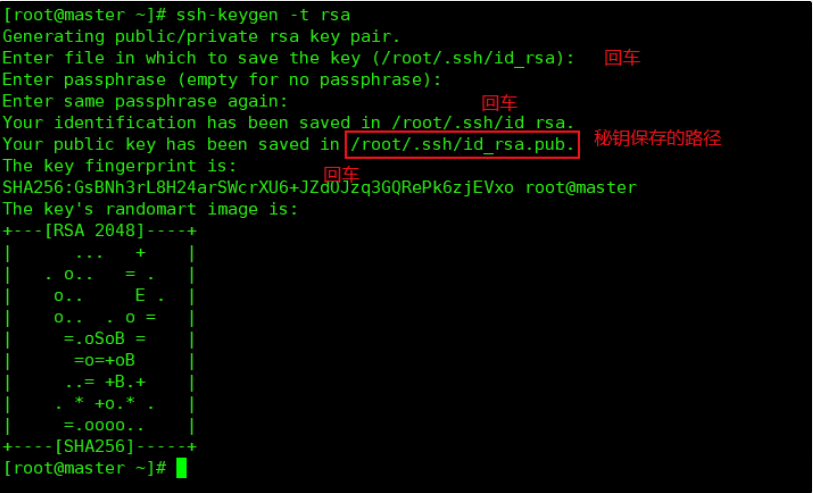
生成authorized_keys文件(只在master节点执行),并发送至各slave(node)节点
[root@master opt]# ssh-copy-id -i /root/.ssh/id_rsa.pub master
[root@master opt]# scp /root/.ssh/authorized_keys root@slave-1:/root/.ssh/
##注意此文件权限务必是644
[root@slave-1 ~]# chomod 644 /root/.ssh/authorized_keys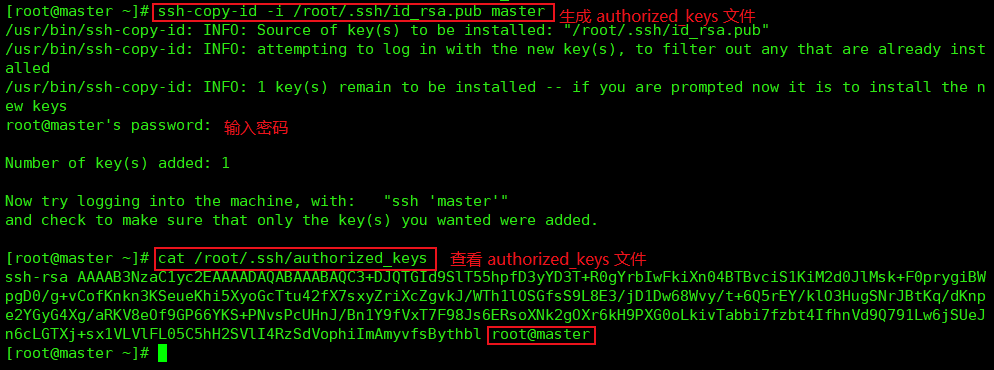
master上测试免密登录
[root@master opt]# ssh slave-1
Last login: Wed Jun 23 15:06:53 2021 from 192.168.0.118")
hadoop系统变量路径在安装目录为/usr/local/big/hadoop-2.9.2的etc/hadoop/下,分别编辑如下
[root@master hadoop]# hadoop-env.sh# export JAVA_HOME=${JAVA_HOME} (注释掉)
export JAVA_HOME=/usr/local/jdk1.8.0_291/ (添加上)
# export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"} (注释)
export HADOOP_CONF_DIR=/usr/local/big/hadoop-2.9.2/etc/hadoop (添加上)[root@master opt]# source hadoop-env.sh[root@master hadoop]# vim core-site.xml##在<configuration>*</configuration>添加
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS 的 URI,文件系统://namenode标识:端口</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoopData</value>
<description>namenode 上传到 hadoop 的临时文件夹</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>[root@master hadoop]# vim hdfs-site.xml##在<configuration>*</configuration>添加
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoopData/dfs/name</value>
<description>datanode 上存储 hdfs 名字空间元数据</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoopData/dfs/data</value>
<description>datanode 上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>副本个数,默认配置是 3,应小于 datanode 机器数量</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>staff</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave-1:50090</value>
</property>[root@master hadoop]# vim yarn-site.xml##在<configuration>*</configuration>添加
<!-- Site specific YARN configuration properties -->
<!-- 用于存储本地化文件的目录列表 -->
<!-- 创建目录 mkdir -p /usr/local/big/hadoop-2.9.2/list -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/big/hadoop-2.9.2/list</value>
</property>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 yarn 的 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- 忽略虚拟内存的检查 虚拟机上设置有很大用处 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced for containers</description>
</property>
<!-- yarn 分配的内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3276</value>
</property>
<!-- 每台机器最大分配内存,超过 报异常 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3276</value>
</property>
<!-- yarn 分配的 CPU 个数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<!-- 每台机器最大分配CPU个数,超过 报异常 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>[root@master hadoop]# vim mapred-site.xml## 在<configuration>*</configuration>添加
<!-- mapreduce 运行时的框架,可以是 local, classic or yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapreduce 历史任务的地址端口 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- MapReduce JobHistory 服务器 Web UI 主机:端口 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>[root@master hadoop]# vim slaves删除默认 localhost
添加集群主机名
master
slave-1[root@master hadoop]# mkdir -p /home/hadoopData[root@master hadoop]# scp /usr/local/big/hadoop-2.9.2/ root@slave-1:/usr/local/big/
##此步骤如手动以配置无需执行
[root@master hadoop]# scp /etc/profile root@slave-1:/etc/[root@master hadoop]# hdfs namenode -format
[root@master hadoop]# ../../sbin/start-all.sh##node节点如遇到resourcemanager服务未启动,执行如下启动即可
[root@slave-1 hadoop]# ./yarn-daemon.sh start resourcemanager[root@master hadoop]# jps
8000 Jps
17720 DataNode
18190 NodeManager
17535 NameNode
18063 ResourceManager")
[root@slave-1 opt]# jps
5169 SecondaryNameNode
11137 Jps
5762 ResourceManager
5052 DataNode
5261 NodeManager")
http://192.168.0.200:50070/、http://192.168.0.200:8088/
")
")
六、Hadoop集群部署常见问题bug汇总
1、如若配置secondaryNamenode到其他node节点
方法:修改master主节点hdfs-site.xml文件如下配置
<property>
<name>dfs.http.address</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave-1:50090</value>
</property>")
2、持续 更新...
提示:如遇链接失效,请在评论区留言反馈
